Some Remote - Local - User Processing Issues
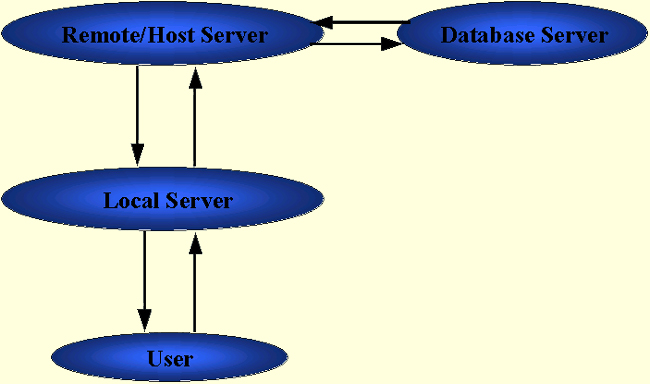
| Introduction. One of the major issues we need to deal with has to do with which computer should do the processing during a web interaction. Below is a diagram illustrating a simplified view of the major contributors to a web processing interaction. |
| This diagram obviously leaves out things like firewalls,
routers, switches and hubs. But it focuses on the machines on the
internet that are likeliest to do certain processing. Think about what happens when you go to a favorite website to get some information. Essentially, you type in a URL on your computer. This sends a request to some local devices, including a local server, that act as a gateway to the Internet/WWW. This request is then sent to the remote server via a number of routers. We call it remote since it is furthest away from the user. We will also refer to this server as the host server. It is likely that you will then download a certain amount of information from this remote server, through your local devices to your computer. In this sequence of events different machines act as servers and/or clients at different times in the interaction. Reiterating, some of the major issues in web development are
For an example think about when you visit this course webpage. You send a request to the faculty server through your browser. The faculty server sends HTML to your browser and the browser interprets it to give you the image on your screen. You do not really maintain an active connection with the server. The faculty server doesn't really even identify you or remember you visited, at least I haven't written in any code so that my pages will do this. This is called a stateless interaction. The page is cached on your computer/client, so that if you move away from it and come back in a pretty short amount of time you don't actually send another request to see the page to the server, you look at your cached copy. If I have updated the page in between your visits you would need to reload/refresh the page to get the most recent version from the server. Now, think about when you visit a site like comedycentral.com. You send a request to their server through your browser. The comedycentral server is also likely to send almost purely HTML to your browser and largely forget that you just made the request. You do not really maintain an active connection. They might have some extra code written so that they write something to your cookies for their future reference. Using cookies allows comedycentral to maintain some persistent information about you. They are more likely to write it to your cookies because they don't want to be storing that much information and they definitely don't want to be storing information on their server for all of their hits. They have also written some small animations, maybe packaged as GIF images or Flash, for you to process on your computer. This definitely increases the download duration, though it gives more life to their page. This sort of trade off is important to remember. Now consider the homepage for barnesandnoble.com. It has a bit more opportunity for interaction. There are some simple animations, but nothing too complex. They don't want you to get frustrated downloading their page and go elsewhere. But you will notice that they also have a little textbox and drop down combo box to help you find things like books and DVDs on their site. If you fill in the textbox and submit your request they make use of a database on their server to give you feedback on the products they have that are relevant to your request. This sort of processing is not something that could be done on your computer. By the same token, they are not going to tie up the network, their server and your machine to download their entire database so that you can do the searching on your own machine. These are some common and realistic examples of client-side and server-side web processing. We will talk about this more later in this page and in the course. Some Platform Issues. It is often the case that a user is running some form of Windows or maybe Mac-OS. This is pretty universally true on this campus. Some version of UNIX or Linux are two other prevalent operating systems. The local network operating system is likely to be either UNIX, Windows-NT, Novell or Linux. The remote network operating system will often be different than the local NOS. As you can see this gets quite complicated. So think about the sorts of platform issues that exist just within Quinnipiac. QU is almost entirely committed to a Windows-NT type network. Users are almost entirely using Windows 9x. Yet the School of Communications and some sciences usually use Macs. The CS program in Liberal Arts emphasizes Linux. Within Business we will emphasize Windows-NT, but I am pushing to implement a Linux server for a variety of reasons. A couple other faculty have serious intentions of implementing an Oracle server, though this is much more easily said than done. Oracle is expensive! On this campus users are browsing the web almost exclusively with Netscape or Internet Explorer. When I was working at Rider University in the recent past, lab machines were primarily Windows 9x with a fair number of Macs in the Sciences and Education. They were using Novell to connect everything. Since they had three legacy VAX super-minis running VMS, two were used as file servers and one of these two was the mail server. They were using an old version of Datatel, even though they had purchased it recently for $1.5 million, so that they could still run it on a VAX mini using VMS. They had started to add servers specifically for certain specialties such as CIS. The CIS server was an NT server of sorts. The computing environment was surprisingly primitive in many ways, but one of the reasons they had stayed with VMS was because their directors/system administrators understood it thoroughly. Thus it was the case that things largely worked. Obviously you can imagine a large variety of internal configurations for nodes on the web. I have described just a couple. You can expect one of your first homework problems to require you to give a similar description for some node on the web. Sometimes the nodes are simpler, many times they are even more complicated. But now we also need to develop some background about some more major issues. Browser and Connection Issues. Even if we limit our view of the browser universe to Netscape and Internet Explorer a developer still needs to be aware of several things. Web designs must also always consider download times, the bandwidth available for the person connecting to the web. This is important both for the local network and server capacity and the user's capacity. Consider the 3Mbps we recently had on this entire campus. Functionally, this seems to translate into 1Kbps download/upload rates for me. Terrifying! Consider situations where someone is dialing up through an ISP and cannot realistically get more than maybe 20Kbps. These sorts of considerations must influence the decision making of a successful web developer. Most everyone has had the experience of not being able to hear certain music or sounds that are supposed to be available on particular webs. This may well be due to compatibility issues. Netscape and Microsoft have both developed features that can only be seen on their browsers and they certainly seem to be trying to control development techniques. We won't get into a deep discussion of these different features at this point in time though we are likely to accumulate discussion on these issues over the semester. What I am trying to motivate with this little survey is the necessity of finding design approaches that will work across different platforms regardless in every way possible. Jumping on the wagon of implementing every new spiffy feature that can be used will certainly result in loss of compatibility and increased download times. Script Versus Compiled Code. At present I want to say a very little about some other distinctions that need to be made. Since everyone should have some background in Visual Basic, let's assume you are working in Visual Basic. Because of this we also need to assume that the potential users are running Windows of some appropriate form. Most of this discussion will generalize to other languages quite easily.
These are not easy issues to deal with or easy questions to answer even when you are working in something like VB. Next I want to develop an example to illustrate some of these issues. Consider the following real situation. Back in the early nineties I worked with a marketing colleague to develop a simulation for teaching pharmaceutical sales reps to want to use their new laptops, to learn about the advantages and capabilities of databases, and how to make use of these databases to improve their sales call planning and tour routing. Things have changed so that the program was no longer needed by pharmaceuticals. On the other hand, we have updated it and included it with Sales Management textbooks so that college students can learn certain things before they went looking for jobs. Rather than go into the details of the program I want to talk about its support and deployment. So the book authors and publishers wanted me to develop a web with background discussion, tutorials and a place for users to download the program.
The authors and publishing company did not want to assume the users had fast internet connections so we ended putting the install on a CD. This is something the publishing company didn't want to do, but had to do. How Do CGIs Fit Into This Picture? CGIs, Common Gateway Interfaces, were designed to give a client more computing power on the server. Essentially it involves allowing the client to run an executable on the server that interfaces with them. This could have a lot of advantages, code would already be tested and in executable form, it might often be the case that very little would need to be downloaded. Unfortunately, it also has some major disadvantages. Every user running the program requires some space on the server in order to execute the program. For example, if we had tried to do our training simulation as a CGI we could have had potentially thousands of simultaneous users. Students in classroom labs at several places in the country would likely end up trying to run the program simultaneously. It is one thing to handle download requests for web pages, it is entirely more server intensive to require simultaneous execution of interactive and ongoing programs. This is particularly true since the simulation would require the user to be connected to the CGI for a fairly extended period of time at each sitting. On the other hand, many web sites make use of CGIs to compute things like local taxes and/or shipping charges. These computations require well defined inputs and the CGI code is pre-compiled so it executes more quickly than scripts. The time for the user and seller to obtain these results for their purchase is measured in micro-seconds. In order to present an application where it is unclear whether a CGI is better or worse consider the following. I intend on developing a web site that will make use of CGIs or maybe Java Servlets to help people assess computer system performance. The computations are complex and it is unlikely we can assume the clients will have certain computational capabilities. While the interaction durations could be fairly long, the number of users is definitely going to be quite small. Two Major Strategies. We have outlined a large of variety of issues. In reality these situations are more complicated than I've described. Trying to consider all these issues when developing an overall web development strategy is nearly impossible, but the reality is you must deal with at least what we've described so far. At this point I want to describe what I consider to be two of the main strategies for dealing with these issues on the web. I will call one the client-side strategy, the other I will call the server-side strategy. These discussions will be considerable simplifications and will likely be enhanced over time, but hopefully they will give you some important insights.
Well these will definitely be elaborated later and fleshed out more in subsequent pages. For many web processing strategies, scripts, programs of uncompiled code are processed. If they are executed on the remote/host server it is called server-side scripting because the code is executed and the results are passed across to the user as HTML code that shows up on a web. Client-side scripting involves downloading the script to the user's machine where it is executed. Each has its advantages. Static and Dynamic Webs. It used to be that the web was composed entirely of what some people call static pages. They could be downloaded/accessed, but the only real way to interact with them was to click hyperlinks so that you moved to another largely non-interactive or static page. They might have photos or words, but there was very little activity on them and user input was limited to selecting URLs. These sorts of pages don't take full advantage of the capabilities provided by the web. What if the developer wants the user to see some sort of animation? Or what if the developer wants the user to get some feedback based on what they choose on the page, or even hover over. What if a user wants to interact with the remote/host server to search, purchase items or give their feedback? These user and host needs are moving beyond relatively static interactions to more dynamic interactions. Some of these interactions require access to the host server in order for certain things to be done. Other things can be done on the user's computer. Server Side Processing. As we've discussed, these interactions can be brought about by client side scripting or by server side scripting, though often times not both. As far as within the realms of costs that can be assumed by the businesses I have done work for there are three major ways to develop server side processing.
When you access something on the web the remote server is often involved in the processing as little as possible. This is definitely going to be the case for downloading what some people call static pages, information pages or non-interactive pages. Even if they involve a lot of client side script being executed by the user's machine, relative to the server they are not demanding many resources. I prefer to classify web pages as sitting someplace between totally passive and totally active depending on the amount of server and user activity they require. A passive server is like the campus map that sits over by the end of the classroom wing of Lender SB. Many different clients (people trying to find something) can be using the server (map) at the same time. But the server (map) sits passively waiting for people to arrive. When it is used it doesn't really interact with the client/user. An active server is more like a person who takes your money to get into a sporting event and gives you directions while answering your questions. But back to our topic, server side scripting pages typically contain two parts:
The programmatic code can be written in a number of scripting languages. The most common for ASPs are VBScript, JavaScript, PerlScript and Python. The names of all of these except Python give away their source language. While I am certain many of you have great interest in mastering the wily ways of the Python, particularly those of the one eyed kind, that's not what we will do in this course. Since I am confident that all of you have taken at least one course in Visual Basic and we are developing in the Microsoft realm using VBScript as our ASP scripting language. With JSPs and PHP there are more specific languages. |